[toc]
基础
自动装箱和拆箱
部分基础数据类型与对应的包装类进行运算时,编译器自动进行转换(装箱:valueOf,拆箱:intValue、floatValue…)
int对应包装类Integer会缓存-128~127范围的整型
short对应包装类Short会缓存-128~127范围的短整型
long对应包装类Long会缓存-128~127范围的长整型
char对应包装类Character会缓存0~127范围的字符(java的char占两个字节存的是unicode码,表示数据范围0~65525)
byte对应包装类Byte会缓存-128~127范围的字节,即byte所表示的数据范围都会被缓存
boolean、float和double没有缓存
集合
List
ArrayList与LinkedList
Map
HashMap、LinkedHashMap、TreeMap
LinkedHashMap:了解基本原理、迭代顺序(插入序、访问序)、如何用它实现LRU
TreeMap:了解数据结构(红黑树,按key排序的二叉查找树)、了解其key对象为什么必须要实现Compare接口、如何用它实现一致性哈希(tailMap方法)
TreeMap实现一致性Hash
参考 https://www.cnblogs.com/DengGao/p/6387708.html
Set
由对应的map实现
ThreadLocal
- 魔数
魔数:0x61c88647 (32bit无符号数:2654435769,32bit有符号数:-1640531527),是2^32*0.618(黄金分割点)
目的:使用斐波拉契散列法,使得散列出的值更均匀
- ThreadLocalMap
ThreadLocaMap存储的key-value是key为ThreadLocal对象的弱引用,在ThreadLocal被设置为null后,在下次gc时ThreadLocal被回收掉,但是value还被线程的ThreadLocalMap强引用,导致内存泄露。
一般在使用ThreadLocal时一般将ThreadLocal定义为static属性,这样ThreadLocal一直存在着强引用,key也不能为null,然后在任何时候都可以手动调用remove进行清除。所以在使用时也要注意手动remove。
2.1 ThreadLocalMap在扩容的时候会将entry的key为null所对应的value设为null,help the gc(减轻内存泄露)
2.2 在每次get、set时都会清除key为null所对应的value为null,减轻内存泄露
2.3 不再使用set进ThreadLocal的值后,调用ThreadLocal的remove方法显式地从ThreadLocalMap删除掉,避免内存泄露
-
ThreadLocal和InheritableThreadLocal区别
3.1 InheritableThreadLocal里设置的值在子线程可以get到(创建子线程时会从父线程拷贝到子线程)
-
ThreadLocalMap采用数组保存Map.Entry,插入查找值时采用开放地址法
-
由于采用开放地址法,在hash冲突是默认查找相邻下一个位置是否可用,因此在清除null key时会有特别的移动操作来保证hash的顺序正确性(参考方法replaceStaleEntry)
-
ThreadLocal、ThreadLocalMap之间关系图

异常
checked异常:必须被捕获或抛出,例如IOException。因此这类异常在编写代码时就可以提醒程序员会出错的地方,程序员可以根据实际情况选择捕获或者抛出。
unchecked异常:例如NPE,运行时异常,不需要被捕获,减少try-catch,代码可读性增强
自定义异常:
继承自Exception:checked异常,必须被捕获或抛出
继承自RuntimeException:unchecked异常,不需要被捕获,如果抛出异常则静默报错
Spring
bean的生命周期 https://www.cnblogs.com/v1haoge/p/6106456.html
循环依赖问题: https://developer.aliyun.com/article/766880
spring cloud 全家桶、AOP的实现、spring事务传播
常见问题
java动态代理和cglib动态代理的区别(经常结合spring一起问所以就放这里了)
属性注入和构造器注入哪种会有循环依赖的问题?
BeanFactory与FactoryBean的区别
Dubbo(或其他Rpc框架)
了解一个常用RPC框架如Dubbo的实现:服务发现、路由、异步调用、限流降级、失败重试
常见问题
Dubbo如何做负载均衡?随机、轮训、加权轮询、加权随机、一致性hash、最少活跃
加权轮询
加权随机
- 根据服务器的权重计算总的权重值totalWeight
- 计算总权重为上限的一个随机值:random.nextInt(totalWeight)
- 判断随机值落在服务器权重哪个区间,并返回相应的服务器信息
一致性hash
hash环、机器映射、数据或调用参数映射、虚拟节点
实现:需求机器hash值在hash环上排序,数据或调用参数hash值在hash环上找到最近节点
hash函数要选择散列性能好的
TreeMap实现排序,taiMap返回大于等于某个hash值的subMap,返回firstKey对于最近阶段hash
虚拟节点:确定1个真实节点对应多少个虚拟节点,然后确定对应规则(比如真实节点192.168.0.1:1234,虚拟节点5个,对应规则为字符串拼接&&VIR0~5,则虚拟节点为192.168.0.1:1234&&VIR0、192.168.0.1:1234&&VIR1、192.168.0.1:1234&&VIR2、192.168.0.1:1234&&VIR3、192.168.0.1:1234&&VIR4、192.168.0.1:1234&&VIR5)
最少活跃
- 统计每个服务器的活跃数aciveNum(每次调用前自增,每次调用完成后自减,数值代表正在处理的请求数也就是活跃数,活跃数越小说明服务器负载越小)
- 遍历找出最小活跃数的服务器,并返回相应服务器的信息
Dubbo如何做限流降级?超时、故障、重试(幂等性)、降级(mock)、熔断(开、关、半开关状态)
幂等性
定义:相同参数多次调用接口和一次调用接口的产生效果是一样的
实现:
-
业务层面:
一: 使用token机制,每次请求都是一个新的token
二:状态机,只有对应的状态下才允许执行相应的操作,并且在操作成功后转入下一个状态
三: 加锁(如本地锁、分布式锁)
-
数据库层面:
一: 新增操作时进行唯一索引字段判断
二:修改操作时进行时间戳或者旧值判断(乐观锁)
三:悲观锁(select for update)
Dubbo如何优雅的下线服务?https://www.cnkirito.moe/dubbo-gracefully-shutdown/
-
JVM提供了优雅停机的接口:Runtime.getRuntime().addShutdownHook
-
Dubbo层面注册优雅停机接口:进行服务下线和资源释放
1
2
3
4
5
6
7
8
9
10
11
12Registry 注销
等待 -Ddubbo.service.shutdown.wait 秒,等待消费方收到下线通知
Protocol 注销
DubboProtocol 注销
NettyServer 注销
等待处理中的请求完毕
停止发送心跳
关闭 Netty 相关资源
NettyClient 注销
停止发送心跳
等待处理中的请求完毕
关闭 Netty 相关资源
Dubbo如何实现异步调用的?
1. Future:获取结果只能阻塞获取或者轮询
2. CompletableFuture:多个异步串联、组合执行,异步指定回调结果处理lambda等
RocketMq(或其他消息中间件)
了解一个常用消息中间件如RocketMq的实现:如何保证高可用和高吞吐、消息顺序、重复消费、事务消息、延迟消息、死信队列
常见问题
RocketMq如何保证高可用的?
主从配置+同步复制/异步复制、发送端消费端可配置有限次自动失败重试、重试队列、死信队列
RocketMq如何保证高吞吐的?
commitLog文件顺序写、单机支持多大5万的消费队列、磁盘文件内存映射零拷贝读取、消费并行度
RocketMq的消息是有序的吗?
发往同一个队列的消息是有序的,顺序消息发送使用同步发送,顺序消息消费原子性操作:每次消费一条消息成功后手动提交offset
RocketMq的消息局部顺序是如何保证的?
发往同一个队列的消息是有序的
RocketMq事务消息的实现机制?
- 发送半消息
- 本地事务执行
- 根据本地事务执行结果发送commit或rollback
- 3步未收到的话定时任务回查本地事务执行结果状态
- 根据3、4的结果确定是否将半消息投递到队列以允许下游消费
- 下游消费,失败重试加重试队列+死信队列保证消费成功
RocketMq会有重复消费的问题吗?如何解决?
重复发送、重复消费;解决:消费端保证消费接口的幂等性
RocketMq支持什么级别的延迟消息?如何实现的?
发送延时消息时先把消息按照延迟时间段发送到指定的队列中(rocketmq把每种延迟时间段的消息都存放到同一个队列中)然后通过一个定时器进行轮训这些队列,查看消息是否到期,如果到期就把这个消息发送到指定topic的队列中。延时消息支持指定时间间隔的延时:1s、 5s、 10s、 30s、 1m、 2m、 3m、 4m、 5m、 6m、 7m、 8m、 9m、 10m、 20m、 30m、 1h、 2h
RocketMq是推模型还是拉模型?
基于长轮询实现:伪推模型、拉模型
Consumer的负载均衡是怎么样的?
在集群消费模式下,一个消费组里面有多个消费者订阅了一个主题,此主题有多个消息队列(MessageQueue),负载均衡组件就将这些消息队列平均分给消费组里面的消费者;策略:平均(默认)、轮询、一致性hash等
Redis(或其他缓存系统)
redis工作模型、redis持久化、redis过期淘汰机制、redis分布式集群的常见形式、分布式锁、缓存击穿、缓存雪崩、缓存一致性问题
常见问题
redis性能为什么高?
单线程的redis如何利用多核cpu机器?
redis的缓存淘汰策略?
redis如何持久化数据?
redis有哪几种数据结构?
redis集群有哪几种形式?
有海量key和value都比较小的数据,在redis中如何存储才更省内存?
如何保证redis和DB中的数据一致性?
如何解决缓存穿透和缓存雪崩?
如何用redis实现分布式锁?
Mysql
事务隔离级别、锁、索引的数据结构、聚簇索引和非聚簇索引、最左匹配原则、查询优化(explain等命令)
推荐文章:
http://hedengcheng.com/?p=771
https://tech.meituan.com/2014/06/30/mysql-index.html
http://hbasefly.com/2017/08/19/mysql-transaction/
常见问题
Mysql(innondb 下同) 有哪几种事务隔离级别?
不同事务隔离级别分别会加哪些锁?
mysql的行锁、表锁、间隙锁、意向锁分别是做什么的?
说说什么是最左匹配?
如何优化慢查询?
mysql索引为什么用的是b+ tree而不是b tree、红黑树
分库分表如何选择分表键
分库分表的情况下,查询时一般是如何做排序的?
zk
zk大致原理(可以了解下原理相近的Raft算法)、zk实现分布式锁、zk做集群master选举
常见问题
如何用zk实现分布式锁,与redis分布式锁有和优缺点
java传参方式
-
环境变量
1
$ SPRING_APPLICATION_JSON='{"acme":{"name":"test"}}' java -jar myapp.jar
-
系统变量
1
$ java -Dspring.application.json='{"name":"test"}' -jar myapp.jar
-
命令行参数
1
$ java -jar myapp.jar --spring.application.json='{"name":"test"}'
QPS估算
二八原则:80%的流量集中在20%的时间里
比如:一天的PV是1000万,则峰值QPS为:1000,0000 * 0.8 / (86400*0.2)= 460
所以接口的QPS需要达到460
电脑部件处理时间数量级对比
CPU:秒
内存:分钟
磁盘:天/月
局域网:年
互联网:百年
1.8 HashMap多线程不安全
举例说明:同时put两个 key1-value1 和key2-value2时,如果key1和key2的hash值相同,则产生hash碰撞,将放到同一个index下的链表上,正确情况是:链表上有两个元素:一个是key1-value1节点,一个是key2-value2节点。但是多线程下可能出现都向同一个Node的next去添加新节点的情况,此时前一个添加的node将被后面的覆盖,导致前一个put的key-value丢失
1.8 ConcurrentHashMap Bug
computeIfAbsent函数添加节点的时候如果在computeFunction里有递归调用或者修改Map的操作,将导致死循环。1.9修复了此bug,会抛出ConcurrentModifyException
多线程

线程池
JDK原生线程池:接收任务大于核心线程数后,会先将任务放到阻塞队列,只有队列满了后才新创建线程。这种线程池模型适合处理CPU密集型任务。
Tomcat/Jetty/Dubbo:自建线程池或者扩展自JDK原生线程池:接收任务大于核心线程数后,会先创建新的线程来处理任务,只有当前活跃线程达到最大线程数后才将任务放到阻塞队列。这种线程池模型适合处理IO密集型任务。
JVM
自动内存管理:
JVM之类加载:java虚拟机是字节码执行引擎,提供跨平台特性。虚拟机读入二进制字节码流(类加载阶段),默认是双亲委托加载模型,SPI接口定义需要bootstrap类加载器去加载第三方接口实现类,但是双亲委托加载模型限制了bootstrap类加载器不可以加载用户类,因此引入了线程上下文类加载器(默认为App类加载器),将第三方类加载到线程上下文加载器中去
JVM之内存模型:每个线程独享的工作内存、所有线程共享的主内存、并发控制提供语言层面的volatile、synchronized
JVM之内存区域划分:线程共享:堆内存、直接内存、元数据区;线程独享:线程栈、本地方法栈、程序计数器
JVM之内存管理:

1. 垃圾回收算法:
-
年轻代:Serial、ParNew、Parallel Scavenge、G1
* Serial特点:单线程收集,适合单CPU场景,执行GC时完全STW,可以与老年代CMS搭配使用 -
ParNew特点:多线程收集,适合多CPU场景,执行GC时完全STW,关注尽量缩短GCSTW时间,可以与老年代CMS搭配使用
-
Parallel Scavenge特点:多线程收集,适合多CPU场景,执行GC时完全STW,关注吞吐量优先,可以使用自适应策略调整年轻代、老年代大小
* G1特点:分代收集,年轻代使用复制算法;将内存分成大小不等的Region,只对需要回收的Region执行GC,提高了并发程度。缺点:Region大小固定对应连续大内存的分配容易导致OOM -
老年代:Serial Old、Parallel Old、CMS、G1
-
Serial Old特点:Serial的老年代版本
-
Parallel Old特点:Parrallel Scavenge的老年代版本
-
CMS特点:将GC细分为四个步骤,将STW的时间缩短;
-
初始标记:STW
-
并发标记:GC线程和用户线程并发执行
-
重新标记:STW(为什么要进行重新标记,因为并发标记过程中,用户线程会修改对象间的引用关系,会导致浮动垃圾的产生以及对象的误删除。浮动垃圾可以忍受,但对象的误删除是不能接受的。所以重新标记阶段主要是防止对象引用关系变化导致的误删除,当然也能减少浮动垃圾 。参考:https://zhuanlan.zhihu.com/p/108706654
-
并发清除:GC线程和用户线程并发执行(会继续产生浮动垃圾)
提高了并发度的同时,CPU、内存占用增加,提供CMSInitiatingOccupancyFraction参数表示老年代使用量达到多大比例就进行FullGC,默认为68%
基于标记清除算法,导致内存碎片,提供UseCMSCompactAtFullCollection参数表示在FullGC时执行内存碎片整理,提高CMSFullGCBeforeCompaction参数表示几次FullGC后才执行一次内存碎片整理。
-
-
G1特点:分代收集,老年代使用标记整理算法,没有内存碎片。引入可预测的的停顿模型来降低STW时间,提供MaxGCPauseMillis参数设置最大GC停顿时间供JVM参考。参考:https://zhuanlan.zhihu.com/p/54048685
-
-
Java8 默认GC是年轻代:Parallel Scavenge + 老年代:Serial Old;对应的JVM参数是:-XX:+UseParallelGC
可通过命令查询java的默认GC:java -XX:+PrintCommandLineFlags -version
可通过命令:jps -v 查出运行中的JVM进程,然后:jinfo -flag UseParallelOldGC pid,即可知道是否使用这个GC
-
G1对大内存更有优势(4核8G以上),java9以上的 默认GC是G1
-
java10以前FullGC都是单线程的,所以调优目标是尽量不要触发FullGC
-
G1最佳实践:
-
设置堆内存大小:一般将初始堆和最大堆设置一样,避免GC后的内存重新分配。初始堆大小(默认值为机器内存的1/64): -Xms,最大堆大小(默认值为机器内存的1/4):-Xmx
-
不要设置年轻代-Xmn大小
-
设置STW最大停顿时间(默认值200ms):-XX:MaxGCPauseMillis=n
-
设置堆内存占用百分比达到多少时触发一次并发周期(一个并发周期相当于CMS整个周期,期间进行的GC叫混合GC),默认值45:-XX:InitiatingHeapOccupancyPercent=n
-
设置混合GC判定Region为垃圾分区的存活对象比例阈值:-XX:G1MixedGCLiveThresholdPercent=n
-
设置一个并发周期内最多经历几次(默认8)混合GC:-XX:G1MixedGCCountTarget=n
-
增大标记线程数量:-XX:ConcGCThreads=n
-
打印GC日志:
- 滚动输出:-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:path-to-gc-log/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M
- 每天输出一个日志文件:-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:path-to-gc-log/gc-%t.log
-
关闭显示GC:-XX:+DisableExplicitGC
-
-
CMS最佳实践:
-
设置堆内存大小
-
打开老年代内存碎片整理:-XX:+UseCMSCompactAtFullCollection
-
在打开碎片整理时设置多少次FullGC后进行一次内存碎片整理: -XX:CMSFullGCsBeforeCompaction=n
-
设置老年代占用内存比例达到多少开始进行CMS GC(默认68%),后面的GC是JVM自己决定的,这个只是第一次开始进行CMS GC的阈值:-XX:CMSInitiatingOccupancyFraction=n
-
代码执行显示GC:System.gc时默认会执行完全STW的Full GC,打开此参数使用CMS GC:-XX:+ExplicitGCInvokesConcurrent
-
当CMS GC时间过长且是因为重标记时间过长,可以打开此参数,使得在重标记前进行一次YoungGC减小年轻代对象大小,减小重标记全局扫描对象数:-XX:+CMSScavengeBeforeRemark
-
JDK8以前的版本,永久代不会自动被回收。当类加载卸载频繁时,打开此参数回收无用的类和常量,避免永久代区OOM(JDK8及以后不用设置此参数):-XX:-CMSClassUnloadingEnabled
-
设置并发CMS线程数(默认值:ConcGCThreads = (ParallelGCThreads + 3)/4,ParallelGCThreads=8+( Processor - 8 ) ( 5/8 )):-XX:ConcGCThreads=n
-
-
JVM参数调优最佳实践:
-
确定程序稳定运行时活跃数据(多次FullGC后老年代大小)占用的内存总大小:activity_num
-
设置堆内存总大小:4 * activity_num (初始堆大小和最大堆大小设置一样避免内存分配)
-
YoungGC频繁:增大年轻代大小,年轻代晋升老年代动态策略(1、晋升年龄阈值:默认15;2、当累积某个年龄的对象大小超过survivor区的一半时,直接晋升老年代)
-
FullGC频繁:原因:1、老年代不足;2、元数据区限制了大小且新生成类频繁导致频繁FullGC;3、大量年轻代晋升到老年代且老年代存不下;4、主动执行FullGC
-
2. 堆内存划分:年轻代(eden区,survivor1、2区)、老年代、永久代(元数据区,JDK8以后元数据区不使用堆内存,使用本地内存,且根据加载类 的数量动态调整大小,不需要设置参数,如果设置了-XX:MaxMetaspaceSize=n来限制元数据区的最大内存,则可能出现OOM:Metaspace)
3. JVM默认参数查看:java -XX:+PrintFlagsFinal -version | grep HeapSize
4. 工具使用:
1. 查看堆内存使用情况:jmap -heap pid
2. 查看堆中对象数量和大小:jmap -histo pid
3. 生成当前java进程的线程方法调用栈快照:jstack pid
4. 生成堆内存dump文件:jmap -dump:format=b,file=heap.bin pid,然后传回本地使用visualVM分析
java -XX:+PrintCommandLineFlags -version 只打印JVM启动时有修改的参数
java -XX:+PrintFlagsInitial -version 打印JVM所有默认的初始参数
java -XX:+PrintFlagsFinal -version 打印JVM启动后的最终设置的所有参数
JVM监控
-
jmx(线上环境不推荐)
1
-Djava.rmi.server.hostname=127.0.0.1 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1234 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
-
登陆线上机器cmd
1
2
3
4
5top
jps
jinfo
jstack
jmap -
arthas(推荐)
JVM命令行参数
标准选项: - 开头
非标准选项: -X开头
开发选项:-XX开头
命令行参数指定值的三种方式:
-XX:+OptionName
-XX:-OptionName
and -XX:OptionName=
命令行参数指定整数大小比如内存大小时可以在数值后加上后缀表示单位如k、m、g
JVM生命周期
-
Launcher
典型的Launcher:java命令
Launcher的作用:
- 解析命令行参数
- 建立堆空间,设置编译模式(client 或 server)
- 读取环境变量设置,如CLASSPATH
- 读取Main-Class
- 创建并初始化VM(JNI_CreateJavaVM)
- 加载Main-Class(CallStaticVoidMethod)
- 执行完main方法后,检查并清除可能出现的pending exceptions,然后返回相应的exit status
- 销毁VM(DestroyJavaVM)
JNI_CreateJavaVM执行流程
- 1个java进程只能创建1个VM实例,确保不会有两个线程调用JNI_CreateJavaVM方法
- 检查支持的JNI版本,初始化gc logging输出流,初始化用到的OS模块如随机数生成器、内存页等
- 解析传入的命令行参数
- 根据传入的参数进一步创建和初始化相关OS模块,加载相应的lib库
- gc logging输出流初始化完成,代理库hprof、jdi初始化完成
- 初始化线程相关数据结构
- 初始化全局数据结构如event log,synchronization primitives等
- 创建Java main 线程,初始化Java级别的同步器
- 初始化剩余的全局模块
- 初始化VMThread线程(执行VM关键操作的线程)
- 加载Java系统类
- 开启Signal Handler线程等。准备好VM环境了,提高JNI服务
DestroyJavaVM执行流程
Launcher和VM自己都可以调用此方法来结束VM
- 等待直到最后个non-daemon线程执行完成(Springboot应用不退出:使用Async或创建了线程池都会导致有non-daemon线程存在而不会退出;另外同理使用tomcat webserver也不会退出)
- 调用Java层面的优雅关机接口shutdown hook
- 调用finalizers
- 调用VM层面的优雅关机接口shutdown hook
- 关闭各种统计线程、信号处理线程、GC线程等
- 释放JNI调用处理模块,至此,不能再执行Java代码
- 停止编译线程,停止VM线程
- 释放IO、内存资源
- 返回调用者
类加载
类加载的作用:映射全路径类名或接口名到相应的Class对象
JVM会在启动时预先加载核心类如Object、Thread等
VM和特定的ClassLoader类一起配合完成类的加载
类加载阶段:
- 加载阶段:根据类或接口名称查找符合类文件格式的二进制流
- 连接阶段:检查类文件格式,给类静态字段赋值类型默认值
- 初始化阶段:开始执行Java代码,先执行静态初始化
一般只有主动使用类的时候才会出发类的加载和初始化。
类加载委托模型:
Java SE的类加载顺序依次是: the bootstrap class loader, the extension class loader and the system class loader 。
其中bootstrap是JVM实现的类加载器,它负责加载bootpath下的类比如rt.jar包
其中extension class loader加载JRE目录/lib/ext下的类。
其中system class loader是默认的应用类加载器,它负责加载main函数所在类和classpath下的类。
类加载器和类的全路径限定名一起唯一确定一个类。
JVM保证类加载是串行化的,因此类加载也是线程安全的。
JVM锁:java对象锁:java monitor,java对象头:mark word(锁信息、gc年龄、对象hashcode)、类指针、[数组长度]
JVM内部线程:单例VMThread、单例WacherThread、多个GC threads、多个Compiler threads、单例Signal Dispatcher Thread、Finalizer线程和Reference Handler线程
C10K: http://www.kegel.com/c10k.html
BIO、NIO、Netty
nc、strace
Netty
特性
-
IO模型(Linux epoll)
-
线程模型(reactor模式),ChannelPipeline.addLast添加handler时可以提供一个处理业务的线程池(类型:EventExecutorGroup),也可以使用netty之外的自定义业务线程池
区别:
- netty提供的业务线程池可以保证同一个channel的消息可以顺序处理
- 自定义业务线程池,不可以保证以上的顺序,所以要处理资源竞争的问题。
-
高性能队列框架Jctools(类似Disruptor,环形数组+缓存伪共享解决+CAS操作)
1
2
3环形数组:内存连续分配充分利用缓存
解决缓存伪共享:属性之间插入long pading,空间换时间,防止属性变化使得不必要的相邻属性缓存失效
CAS操作:MPSC队列(多生产者单消费者队列),在生产者入队列时,需要操作数组使用CAS操作避免锁竞争 -
零拷贝
1
2
3
4
5零拷贝一般大众所知是 Linux 中一种用于减少在文件(网络)读写过程中用户态与内核态互相切换,内核态数据需要 copy 到用户态的优化手段。在 Java 的中是以 FileChannel.transferTo 来体现。
Netty 的零拷贝分为两种:
一种是使用 FileReigon 封装了 FileChannel.transferTo 操作使得网络读写性能得到优化(基于操作系统的零拷贝技术实现);
另一种是使用 CompositeByteBuf 使用单个 ByteBuf 一样操作多个 ByteBuf 而不需要任何 copy,通过 slice 方法可以讲单个 ByteBuf 拆分为多个 ByteBuf 操作,但是其本质为操作一个 copy。更多的是指代 Netty 中对于数据高效率操作方式。与内核态用户态切换无关。
Netty 对于 ByteBuf 的零拷贝让多种数据组合更加方便。零拷贝最多能减少两次无意义的 copy 操作且大幅减少内核态与用户态的上下文切换。 -
提供基于传输层协议(TCP、UDP)的支持和各种配置
-
提供各种开箱即用的Handler (编解码Codec,流分割LengthFieldBasedFrameDecoder等,空闲检测IdleStateHandler,序列化)
epoll惊群
惊群:多个线程等待同一个事件发生,在事件到来时,所有线程都被唤醒来竞争事件的处理,最后只有1个线程成功获得事件处理,其他线程又回到等待状态,等待下次事件的发生。
epoll_wait设计为等待多种类型事件(accept、read、write、connect)的发生,accept事件只能由1个线程处理,但其他事件比如read事件是可以由多个线程处理的,所以内核对此不做处理,由用户程序处理。
所以在epoll_wait处理accept事件时依然会有惊群问题,netty自己限制只有1个boss线程来处理accept事件,避免了惊群问题。
- accept 不会有惊群,epoll_wait 才会。
- Nginx 的 accept_mutex,并不是解决 accept 惊群问题,而是解决 epoll_wait 惊群问题。
- 说Nginx 解决了 epoll_wait 惊群问题,也是不对的,它只是控制是否将监听套接字加入到 epoll 中。监听套接字只在一个子进程的 epoll 中,当新的连接来到时,其他子进程当然不会惊醒了。
参考文章https://pureage.info/2015/12/22/thundering-herd.html
SpringBoot启动流程
**SpringBoot 监听器:**SpringApplicationRunListeners
1 | EventPublishingRunListener 类在SpringBoot启动时读取AppClassLoader加载目录下的SpringBoot框架JAR包的META-INF/spring.factories文件实例化的 |
SpringBoot配置环境: ConfigurableEnvironment
**SpringBoot应用配置上下文:**ConfigurableApplicationContext
SpringBoot 自动化配置:
spring-boot-xxoo-starter实际上没有任何java代码,只有个pom文件指定了依赖spring-boot-starter,
spring-boot-starter也没有任何java代码,只有个pom文件指定了依赖spring-boot-autoconfigure,
而spring-boot-autoconfigure里则包含了所有springboot官方的starter包所需要的外部依赖及自动配置文件和META_INF/spring.factories
非官方的starter的结构和spring-boot-autoconfigure一样包含了需要的外部依赖及自动配置文件和META_INF/spring.factories
SpringFactoriesLoader类的loadFactoryNames方法,入参为factoryClass和classLoader,根据指定的classLoader,加载该类加载器搜索路径下的META_INF/spring.factories文件,传入的工厂类为接口,而文件中对应的类则是接口的实现类;loadFactoryNames方法返回类名集合,方法调用方得到这些集合后,再通过反射获取这些类的类对象、构造方法,最终生成实例
SpringMVC执行流程

Redis-HyperLogLog
HyperLogLog:redis-HyperLogLog 不精确(0.81%的错误率)的去重统计,比如:网站UV数、访问IP数等
原理:基数估算算法-伯努利实验-根据n次独立实验:抛掷硬币首次出现正面(或反面)所需要的最大次数k_max来估算实验的总次数n:
$$
n = 2^(k_max)
$$
分桶平均:将统计数据划分为m个桶,每个桶分别统计各自的k_max并能得到各自的基数预估值 n ,最终对这些 n 求调和平均得到整体的基数估计值:
$$
n = m * \frac{m}{\sum_{i=1}^{m}{\frac{1}{2^(k_m)}}}
$$
16384=2^14个桶数组,每个桶6bit,一共16384*6/8/1024=12KB,一个key占用内存12KB
pfadd key value:将value取hash生成64bit的字符串,取hash值的前14位来计算桶数组下标,取hash的后50位中首次出现1的位数(0~50之间,6bit可存放到数值64,因此够用),然后放入对应的桶中
pfcount key:根据估算公式:修正因子 * 桶数 * 调和平均数;m为桶的个数16384,得到估算值
$$
const * m * \frac{m}{\sum_{i=1}^{m}{\frac{1}{2^(k_m)}}}
$$
为了节省内存空间,redis不会直接用16384个6bit桶存储1个HyperLogLog对象,而是先用稀疏存储(针对连续多个桶的计数为0进行存储优化,针对连续多个桶的计数都不为0且相等也进行存储优化),再用密集存储(12K,设定稀疏存储转密集存储的阈值)的方式
去重数据结构
布隆过滤器Bloom Filter:存在判断不精确、不支持删除
原理:当一个元素被加入集合时,通过K个相互独立的Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1。
计数式布隆过滤器Counting Bloom Filter:存在判断不精确、支持删除
原理:将位阵列扩展成byte阵列,用多余的bit要存储设置为1的计数器以支持删除操作
布谷鸟过滤器Cuckoo Filter:存在判断精确,支持删除
原理:有两个相关的hash算法将新来的元素映射到数组的两个位置。如果两个位置中有一个位置为空,那么就可以把元素放进去;但是如果这两个位置都满了,那么会随机踢走一个,然后自己霸占这个位置。
bitmap:存在判断精确,支持删除
日志框架使用
面向程序员的只是日志门面,具体需要哪个日志框架,选择相应的桥接器和日志实现框架。
- 刚开始: 第三方日志系统:log4j等
- JDK自带log: JUL(Java Util Log)加入
- 日志门面JCL(Java Common Logging)问世,其他日志实现自己桥接到JCL(桥接器)
- 日志门面SLF4J问世,加上自带日志实现Logback,其他日志实现自己桥接到SLF4J(桥接器 xxx-over-slf4j)
- Log4j2问世,自带日志门面log4j2-api,加上日志实现log4j2-core
至此,日志门面有三个了:JCL、SLF4J、log4j2-api,日志实现有4个:JUL、log4j、logback、log4j2-core
一个字:乱
实际项目中使用日志,应该遵循以下规则:
- 总是使用日志门面:推荐SLF4J
- 只添加一个日志实现的依赖:推荐log4j2
- 使用第三方库,有必要排出第三方库中的日志实现依赖
- 每一个日志的实现框架都有自己的配置文件。使用slf4j以后,配置文件还是做成日志实现框架自己本身的配置文件;比如使用slf4j+log4j2,则需要的配置文件为log4j2.xml
Spring-boot项目默认使用:SLF4J + logback,且把其他的日志都替换成了slf4j
SpringBoot项目使用slf4j+log4j2配置:
1 | <dependency> |
单点登录
秒杀平台设计
问题:高并发、超卖、恶意请求、链接暴露
思路:
应对高并发:微服务、分布式、集群、
缓存穿透:请求一个不存在的数据(解决:1. 缓存空值并设置过期时间 2. bloomfilter先查询是否存在然后再走缓存->DB)、
缓存击穿:大量请求同时请求同一个失效的key(解决:分布式锁+写缓存)、
缓存雪崩:大量key同时失效(解决:分布式锁+写缓存,设置不同的失效时间、服务限流降级)
应对超卖:幂等性、分布式事务、分布式锁
恶意请求:屏蔽特定use-agent、屏蔽频繁访问的ip(guava RateLimiter)
链接暴露:动态url(url加入md5验证)
将请求尽量拦截在系统上游(用户页面-cdn缓存-Nginx负载均衡-服务器集群-Redis-消息队列-Mysql)
业务逻辑优化:要将秒杀商品先加入购物车才可以下单等
容错处理:限流、降级、熔断

算法
单链表反转
动态规划-完全背包问题
排序
1 | 冒泡排序: |
1 | 选择排序:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 |
1 | 插入排序:采用in-place在数组上实现。具体算法描述如下: |
1 | 希尔排序:改进的插入排序,引入一个增量序列(比如:length/2, length/2/2, ... ,1),增量依次递减,每次依据增量对原数组进行分组直接插入排序,待到增量为1时最后一趟插入排序后即完成整个数组的排序。 |
1 | 归并排序:采用分治法,将已有序的子序列合并,得到完全有序的序列;类似增量序列(length/2, length/2/2, ... ,1)当增量为1时的分组自然有序,然后递归合并2,4,8长度分组,由于合并的两个分组已经有序,合并操作很简单如下: |
1 | 快速排序:也是采用分治法,在待排序的数列中,首先要找一个数字作为基准数。为了方便,我们一般选择第1个数字作为基准数(其实选择第几个并没有关系)。接下来我们需要把这个待排序的数列中小于基准数的元素移动到待排序的数列的左边,把大于基准数的元素移动到待排序的数列的右边。这时,左右两个分区的元素就相对有序了;接着把两个分区的元素分别按照上面两种方法继续对每个分区找出基准数,然后移动,直到各个分区只有一个数时为止。 |
1 | 堆排序: |
1 | TimeSort:稳定的自适应的归并排序 |
正排索引
根据文档ID找到对应的文档
倒排索引
根据文档内容的分词找到出现该分词的文档列表
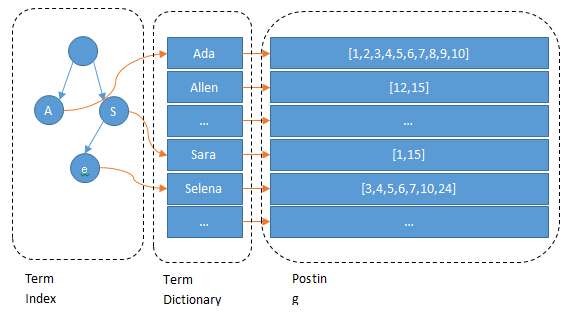
图片来源地址:https://zhuanlan.zhihu.com/p/33671444
- trie树(字典树):找到分词对应于2中的索引offset
- hashmap(内存)或者b-tree(磁盘):根据分词的索引offset快速定位找到文档list
- 文档list可以用skiplist,方便进行并集、交集等运算
- 文档list其实是文档ID的list,另外可以加入分词的出现频率、出现位置等信息,用于对搜索结果进行一个打分排序
集群与分布式
集群:多台服务器运行同一个服务,处理同一件事
分布式:多台服务器各自运行不同的服务,不同的服务之间有相互调用
分布式技术
初期
单体应用:(nginx + server + redis + mysql)一台机器
数据越来越大
单体应用+应用数据分离+mysql主从高可用部署+redis集群高可用部署: (nginx) + (server)+ (redis)+ (mysql)
QPS越来越高
集群应用: (nginx)+ 负载均衡 + (servers)+ (redis)+ (mysql)
应用越来越复杂
应用拆分:(nginx)+ 负载均衡 + (server1s)+ (server2s)+ (server…s)+ (redis)+ (mysql)
应用拆分后就需要:
跨服务调用:RPC、服务统一注册和发现、负载均衡、
服务统一入口:网关和路由
服务容错:熔断、限流、降级
服务间的解耦和异步:消息队列
应用拆分后服务设计原则:无状态、分布式事务、分布式锁
dubbo = RPC + 服务统一注册和发现 + 软负载均衡 + 监控
分布式一致性
分布式一致性通过共识算法来达成
共识算法有个拜占庭问题
共识算法分两类:
-
非拜占庭容错类算法: Paxos、Raft(http://thesecretlivesofdata.com/raft/)
-
拜占庭容错类算法: 实用拜占庭容错算法PBFT(Practical Byzantine Fault Tolerance)、代理拜占庭容错算法DBFT(Delegated Byzantine Fault Tolerant)、工作量证明PoW(Proof of Work)、股权证明PoS(Proof of Stake)、代理股权证明DPoS(Delegated Proof of Stake)
区块链【电子签名、工作量证明(拜占庭容错)、密码哈希函数;分布式一致性、去中心化】:sha256、Merkle 哈希树、非对称加密、签名验签
云上容灾架构




LinkedHashMap实现LRU算法
1 | // 继承LinkedHashMap |
Springboot java -jar 执行原理
JVM实例创建成功后,判断执行方式是jar方式还是class方式,jar方式则会读取jar包META-INF/MANIFEST.MF文件的Main-Class主类名,然后加载并执行
SpringBoot Jar包 Manifest文件如下:
1 | Manifest-Version: 1.0 |
可知Springboot jar包执行的入口main函数在org.springframework.boot.loader.JarLauncher类
JarLuancher类 main函数读取jar包的Manifest文件指定的Start-Class,然后执行真正的Start-Class类的main函数
SpringMVC 执行流程
- Spring容器启动时注册Filter到Spring容器,初始化Filter(调用init方法);注册Interceptor到Spring容器
- web容器(tomcat)接收请求时,首先调用servlet的init方法,此处创建WebApplicationContext,初始化HandlerMappings、HandlerAdapters、ViewResolvers等
- 创建FilterChain,并将Filter加入FilterChain
- Filter过滤链前置处理
- DispatcherServlet.doService
- Interceptor.preHandle拦截器前置处理
- Controller业务处理
- Interceptor.postHandle拦截器后置处理
- Interceptor.afterCompletion拦截器完成处理
- Filter过滤链后置处理
缓存一致性协议MESI
https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
高性能队列Disruptor
ArrayBlockingQueue,入队列和出队列都要加锁。
Disruptor:
- 使用环形数组RingBuffer+利用缓存行64KB的特性用空间换时间让不变的值尽量留在缓存中提供效率
- 数组长度为2的n次方,利用位运算提高效率
- 出队列和入队列通过CAS操作,避免锁开销
Caffeine本地缓存
原理:
- Window-TinyLFU
LFU:Least Frequently Used 一段时间周期内最少使用,淘汰最少访问频率的数据(基于访问频率)
LRU:Least Recently Used 最近最少使用,淘汰最旧的数据(基于访问时间)
Window-TinyLFU:分段 LRU(三级LRU队列:Eden, Probation, Protected; 应对突发流量) + Count-Min Sketch(类似布隆过滤器,频率统计)
- 三级LRU队列
- 读写队列分开,使用RingBuffer作为队列
- 过期策略:
- expireAfterWrite:写后多久过期
- expireAfterAccess:最后一次访问过后多久过期
- expireAfter:自由指定过期时间
- 更新策略:refreshAfterWrite:写后多久再次访问时会去刷新该缓存
- 以上基于时间的策略都是基于时间轮实现的延时任务
- 实时监控:recordStats,参考 https://github.com/ben-manes/caffeine/tree/master/examples/stats-metrics/
- 淘汰监听:removalListener
java类加载与卸载
-
类加载器:Bootstrap ClassLoader、ExtClassLoader、AppClassLoader、自定义ClassLoader
-
类加载默认模型:双亲委托模型
-
系统类加载用户类:线程上下文类加载器(SPI机制就会使用到)
-
Tomcat类加载模型:Common ClassLoader(加载各个webapp和tomcat共同使用的class)、Shared ClassLoader(加载各个webapp共同使用的class)、WebApp ClassLoader(加载每个webapp自己的class)、JasperClassLoader(每个jsp文件对应一个JasperClassLoader)。 JSP热更新就是通过卸载旧的JSP文件的JasperClassLoader,创建新的JasperCLassLoader来加载更新后的JSP文件的。
-
类卸载(GC回收类的Class对象):必须满足条件:
- 不存在引用该Class对象的实例对象
- 该Class对象没在任何地方被引用
- 加载该Class对象的ClassLoader已经被回收
由此可见类卸载条件是很苛刻的,尤其是条件3,很多类都是AppClassLoader加载的,而AppClassLoader在应用程序生命周期内都是一直存在的。只有一些由自定义的ClassLoader加载的类才有可能会被卸载。而且GC时间不可控,即使三个条件都满足,类Class对象也不一定能被及时卸载。
面试
-
简单自我介绍
-
项目经验-用两三句话说清楚项目
1
2
3
4比如光速APP:
客户端:tun2sock(将app的流量全转到代理软件上来)
服务端:提供的方式:SS(协议加密方式)、V2RAY
线路:自动部署、记时、流量统计、限速tun是操作系统支持的虚拟网卡,参考 https://www.cnblogs.com/bakari/p/10450711.html 和 http://arloor.com/posts/other/android-vpnservice-and-vpn-dev/
tun2sock要做的事可以分成三个部分:
- 通过tun网卡拿到手机的所有IP数据包
- 将数据包用sock协议封装
- 将封装后的数据包发送给代理服务器,完成数据的转发
-
SpringBoot优点、自动配置原理、启动流程(干了什么事,用到了什么设计模式)
-
java集合、并发、多线程、JVM
-
netty
-
dubbo vs spring cloud:各自特点,区别,RPC原理(通信方式http、tcp,数据协议hession、json、pb…)
-
消息队列MQ
-
分布式:一致性协议:最终一致性:两阶段提交、TCC、paxo、raft;一致性HASH
-
mysql:事务级别、建表原则、优化方式、分库分表、HA方案(主从备份,读写分离,集群部署)
-
redis:数据类型和各自应用场景,redis实现分布式锁,redis内存50%,redis 哨兵 和 cluster,淘汰策略LRU实现
-
服务运维和监控(限流、降级、熔断)
-
负载均衡方式(分层,DNS【DNS智能解析,DNS污染、DNSSec】…)
-
接口分版本方法
1
2
31. 域名分版本:v1.api.com v2.api.com
2. URL分版本:/api/v1/hello /api/v2/hello
3. 参数分版本:参数加上version字段 -
性能测试
1
2
3
4
5
6
7
8
9//参考 陈皓博客:性能测试应该怎么做 https://coolshell.cn/articles/17381.html
1. 响应时间考量目标综合选择:平均值、中位值、TP值(Top Percentile,TP50,TP90,TP99)
2. 吞吐量(QPS)必须和响应时间挂钩:比如TP99小于100ms时的QPS是1000
3. 吞吐量、响应时间还必须和成功率挂钩:关键系统成功率必须保证100%
//具体步骤
1. 定好前提比如:机器配置,模拟并发请求数(多少个客户端多少时间内多少个请求),TP99值必须在100ms以内,平均响应时间在500ms以内,100%请求成功
2. 在1的限制下测试系统找到最高QPS
3. 用2的最高QPS连续压测系统一段时间,收集系统的指标(CPU、内存、IO等),判断系统的稳定性- 性能测试可以在本机做,得到一个基准值,再和生产环境机器测试一次数据作对比,大概得到一个性能比值,下次性能优化目标就可以定量到本机测试
- 使用Profile工具定位到每个方法的处理时长,对方法进行优化
- 单机优化方式:加本地缓存、本地异步任务线程池配置、Redis Client线程池配置(区分是Netty NIO还是BIO,Netty NIO只需要少量线程池数量,而BIO只能堆线程池数量了),JDBC Client线程池(区分是NIO还是BIO)配置
- 线程池的配置参数: 核心线程数、最大线程数、队列长度的设置要综合考虑CPU、内存、JDBC线程池、REDIS线程池的配置
- 再提升性能,就要上分布式+集群了
-
压力测试
-
浏览器访问www.google.com整个流程
1
21. DNS解析、hosts文件、DNS Server、DNS缓存、DNS记录(A、CNAME)DNS负载均衡
2. http vs https(证书,单向认证【浏览器访问网址都是单向认证】,双向认证) -
自己完成的最有挑战性、最难忘、最成功的事
Linux CMD
pcstat(page cache统计)
1 | go get golang.org/x/sys/unix |
strace
nc
lsof
netstat
tcpdump
pidof
pidstat
sysctl -a | grep xxoo
系统文件描述符限制查看修改:
查看系统配置项意义:man 5 proc
1 | // 1. 系统级 |
docker update容器
docker update --restart=no container-name
docker update --restart=always container-name
Mac本机压测
-
launchctl limit 查看打开文件进程限制
-
修改打开文件进程限制,解决too many open files
sudo vim /Library/LaunchDaemons/limit.maxfiles.plist
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<?xml version="1.0" encoding="UTF-8"?>
<plist version="1.0">
<dict>
<key>Label</key>
<string>limit.maxfiles</string>
<key>ProgramArguments</key>
<array>
<string>launchctl</string>
<string>limit</string>
<string>maxfiles</string>
<string>65536</string>
<string>65536</string>
</array>
<key>RunAtLoad</key>
<true/>
<key>ServiceIPC</key>
<false/>
</dict>
</plist>sudo vim /Library/LaunchDaemons/limit.maxproc.plist
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple/DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>limit.maxproc</string>
<key>ProgramArguments</key>
<array>
<string>launchctl</string>
<string>limit</string>
<string>maxproc</string>
<string>4096</string>
<string>4096</string>
</array>
<key>RunAtLoad</key>
<true />
<key>ServiceIPC</key>
<false />
</dict>
</plist> -
空接口压测到最高8500QPS的参数
1 | [qiaojian@Mac Documents ]% wrk -t5 -c500 -d30s http://127.0.0.1:9091/hello/test1\?name\=qiaojian |
- 使用上一步的参数作为本机压测的基准参数和基准值,去压测其他接口
Object Wait/Notify
1 | 1. 首先每个java对象都可以当作锁使用,synchronized即是基于java对象内置锁monitor的 |
Maybatis一级缓存与二级缓存
一级缓存
-
MyBatis一级缓存的生命周期和SqlSession一致,默认开启。
-
MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
-
MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
-
全局关闭:设置
mybatis.configuration.local-cache-scope=statement -
指定 mapper 关闭:在
mapper.xml的指定 statement 上标注flushCache="true" -
另类的办法:在 statement 的 SQL 上添加一串随机数(select * from table where #{random} = #{random})
-
1 | MyBatis 的一级缓存默认开启,属于 SqlSession 作用范围。在事务开启的期间,同样的数据库查询请求只会查询一次数据库,之后重复查询会从一级缓存中获取。当不开启事务时,同样的多次数据库查询都会发送数据库请求。 |
1 | mybatis: |
二级缓存
- MyBatis的二级缓存相对于一级缓存来说,实现了
SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强,默认未开启。 - MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
- 在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。
缓存和数据库一致性
-
经典模型:Cache Aside Pattern
读:先读缓存,缓存没有,再读数据库并更新缓存
写:先写数据库,再删除缓存
存在问题:删除缓存失败(虽然很少碰到),会导致缓存的旧数据和数据库中的新数据不一致的情况
解决方案:2
-
写数据改为:先删除缓存,再写数据库
存在问题:数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。此时,缓存和数据库的数据又不一致了。
解决方案:3
-
将读缓存为空需要读数据库并更新缓存的读操作和写数据的操作放到本地队列或分布式队列排队并顺序执行
存在问题:性能瓶颈在队列串行化执行
-
如果允许数据暂时的不一致,可以在1或2的基础之上增加定时任务:从DB刷新数据到缓存
HTTP1.0与2.0特性
Stream ParallelStream
Stream ParallelStream默认使用ForkJoinPool线程池,线程数为CPU核数
nohup
java进程接收到SIGHUP(kill -1 process-no)时,进程会退出。nohup启动可以屏蔽SIGHUP信号
Linux性能分析
CPU
上下文切换、top、cpu使用率100%、不可中断进程、僵尸进程、软中断、perf工具
内存
内存buffer与cache、内存泄露定位、swap变高
IO
磁盘IO优化、狂打日志、C10K、C1000K、怎样评估系统的网络性能、DNS解析慢、tcpdump、DDos攻击、网络请求延迟大解决、网络性能优化、网络收发包缓存区
tcpdump教程
https://github.com/mylxsw/growing-up/blob/master/doc/tcpdump简明教程.md
1 | 在服务端进行抓包分析,使用tcpdump |
综合
系统监控、应用监控
Time_Wait&Close_Wait
time_wait是服务器发起主动关闭连接后,连接进入等待2msl的状态,之后才关闭
time_wait等待2msl原因:
- 保证连接被正常关闭
- 防止收到旧连接的数据包
服务器time_wait状态连接太多,解决办法:调整服务器配置参数
1 | 通过调整内核参数解决 |
close_wait是服务器收到被动关闭连接后,连接进入等待应用程序发送fin包关闭连接的状态
服务器close_wait状态连接太多,解决办法:查看应用程序使用socket的地方是否正确关闭了连接
MAC设置测试环境IP转发到本地
开发测试中可能会使用远程的机器地址如172.17.5.49,由于公司安全限制本地连不上或者搭建了本地的环境使用,此时可以添加端口转发,将from 127.0.0.1到172.17.5.49-6379的流量转发到127.0.0.1-6379上来
1 | 一、修改/etc/pf.conf |
计算与存储分离
https://juejin.cn/post/6844904055840440333,阿里PolarDB
任务调度azkaban
分布式链路追踪sleuth
大数据-hdfs+hive+hbase
消息队列-kafka-RocketMQ
线程池TaskDecorator
大数据

底层分布式存储:分布式文件系统HDFS
资源动态调度层:yarn
计算(离线、实时)框架:MapReduce、Spark、Storm、Spark-Streaming、Flink
将SQL转成MapReduce计算函数然后提交给hadoop执行:Hive
大数据NOSQL:
底层分布式存储:分布式文件系统HDFS
NOSQL数据库:HBase
1 | 所有这些技术在实际部署的时候,通常会部署在同一个集群中,也就是说,在由很多台服务器组成的服务器集群中,某台服务器可能运行着 HDFS 的 DataNode 进程,负责 HDFS 的数据存储;同时也运行着 Yarn 的 NodeManager,负责计算资源的调度管理;而 MapReduce、Spark、Storm、Flink 这些批处理或者流处理大数据计算引擎则通过 Yarn 的调度,运行在 NodeManager 的容器(container)里面。至于 Hive、Spark SQL 这些运行在 MapReduce 或者 Spark 基础上的大数据仓库引擎,在经过自身的执行引擎将 SQL 语句解析成 MapReduce 或者 Spark 的执行计划以后,一样提交给 Yarn 去调度执行。 |
1 | 这里相对比较特殊的是 HBase,作为一个 NoSQL 存储系统,HBase 的应用场景是满足在线业务数据存储访问需求,通常是 OLTP(在线事务处理)系统的一部分,为了保证在线业务的高可用性和资源独占性,一般是独立部署自己的集群,和前面的 Hadoop 大数据集群分离部署。 |
使用iperf3工具测试局域网带宽
Filter vs HandlerInterceptor vs Aspect
消息队列选型
kafka:高吞吐量(顺序读写磁盘、MMAP内存映射文件、零拷贝 、生产者消费者批量发送sendfile、GZIP或Snappy压缩【减少网络传输数据量】)
RocketMQ:高可靠性
| Kafka | RocketMQ |
|---|---|
| Broker是个物理概念, Master/Slave是个逻辑概念,Master/Slave是通过zookeeper选举产生的。一个Boker对应一台机器。 | Broker是个逻辑概念, Master/Slave是个物理概念。Master/Slave的角色是通过配置固定的。一个Master或一个Slave对应一台机器。 |
| 使用zookeeper管理Topic/queue和物理机器的映射关系 | 使用NameServer管理Topic/queue和物理机器的映射关系 |
| 异步刷盘(可配置异步刷盘时间间隔、消息数阈值) | 同步刷盘,异步刷盘 |
| 同步Replication,异步Replication | 同步Replication,异步Replication |
| 单机写入TPS约在百万条/秒(批量发送) | 单机写入TPS单实例约7万条/秒(不支持批量发送) |
| 单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,Load越高 | 单机支持最高5万个队列 |
| 0.8版本后消费端支持长轮询pull | 消费端长轮询pull |
| 消费失败不支持重试 | 消费失败支持定时重试,每次重试间隔时间顺延 |
| 单个partition里的消息是有序的 | 单个message queue里的消息是有序的 |
| 不支持定时消息 | 支持定时消息 |
| 不支持消息查询 | 支持消息查询 |
| 不支持分布式事务 | 支持分布式事务 |
| 不支持Broker端的消息过滤 | 支持Broker端的消息过滤 |
| 消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费,每台机器只能开启一个线程 | 顺序消费方式并行度同Kafka完全一致;乱序方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000; |
Kafka存储结构:一个Topic对应多个Partition,每个Partition一个目录,Partition目录下由多个Segment文件和索引组成
RocketMQ存储结构:所有Topic的消息写入CommitLog文件,将Topic/Queue的Offset写入对应的每个ConsumerQueue文件

Spring-Kafka提供了消费失败重试机制和死信队列机制
Linux文件IO:read/write(适用场景:对单个文件不频繁的少量读写)、mmap(适用场景:对单个大文件的频繁大量读写)、sendfile(这个系统调用将 mmap() + write() 这两个系统调用合二为一;适用场景:无需修改文件内容,仅仅将文件数据发送到网络)、splice(功能上和 sendfile() 非常相似,但是能够实现在任意类型的两个文件描述符时之间传输数据;而在底层实现上,splice()又比 sendfile() 少了一次 CPU 拷贝)
IO参考文章:https://www.jiqizhixin.com/articles/2019-01-21-19、https://zhuanlan.zhihu.com/p/308054212
文件存储结构:
B-Tree:按页写入存在内存碎片,按索引读取历史数据性能更好,数据key在索引文件中只有一份能很好的支持事务
LSM-Tree:将随机写转化为顺序写。牺牲了部分读性能,以此来换取写入的最大化性能,特别适用于读需求低,会产生大量插入操作的应用环境。
使用工具sysbench测试机器cpu、内存、mysql、文件io性能
网络IO测试工具:iperf
文件IO测试工具:fio
Redis vs RocksDB vs LevelDB
Apache Arrow
零拷贝序列化框架,大数据不同机器间协调合作数据传输统一格式:最好的序列化就是没有序列化
Huffman编码
只有在数据的次数或者频率分布不均匀的时候,编码才能产生压缩的作用,若数据分布较为均匀,则压缩效果不明显
gitlab ci/cd & ansible-playbook & supervisorctl
gitlab:代码仓库
gitlab ci/cd:gitlab持续集成/持续部署
ansible:自动化运维工具(批量自动配置、部署、运行命令)
Supervisor: 进程管理
Mysql流式查询
MySQL JDBC StreamResult通信原理浅析
SpringCloudNetflix超时时间配置
参考: https://zhongpan.tech/2020/03/23/029-hystrix-ribbon-feign-relationship/
Feign超时配置:针对偏底层的网络超时配置,粒度可以精确到service
Hystrix超时配置:针对命令执行的熔断超时配置,粒度可以精确到method
ribbon超时配置:针对负载均衡+重试超时配置,粒度可以精确到service
超时设置准则:Hystrix的熔断是在ribbon和http请求超时或失败达到多大比例后进行的操作,所以Hystrix的熔断超时时间一定要大于ribbon和http请求加起来的总时间,不然请求还没完成Hystrix熔断超时时间就触发了熔断。

Linux后台运行进程
1 | [root@VM-0-3-centos ~]# shopt | grep huponexit |
进程id:pid
进程组id:pgid (一系列命令组合在一起形成进程组)
父进程id:ppid
会话id:sid (会话管理多个进程组)
huponexit为off时,会话正常注销退出时,shell后台运行的子进程不会退出,而是变成init进程的子进程。但是会话异常退出时,shell后台运行的子进程还是会退出。
避免会话退出子进程也退出的方式:nohup(或者setsid、disown、()、screen、tmux)
nohup command >/dev/null 2>&1 &
另外注意:默认的输入输出都是创建进程的会话的输入输出设备,因此会话关闭时,程序的输入输出会异常,因此启动命令上要进行输入输出重定向(一般程序没有使用标准输入,因此指定输出重定向即可)
Linux C语言实现daemon进程:https://ixyzero.com/blog/archives/3111.html
Redis实现daemon进程:
1 | void daemonize(void) { |
Tomcat配置

https://cloud.tencent.com/developer/article/1674556
Acceptor线程:处理accept事件,完成tcp三次握手创建socket,然后将Socket封装成PollerEvent事件放入ClientPoller的事件队列
ClientPoller线程:Selector轮训遍历可读和可写事件,然后将可读或可写的Socket传给IO线程池里的IO线程进行处理
IO线程池:真正处理Socket读写以及业务逻辑的地方
BlockPoller线程:用于当IO线程的Socket数据需要多次读写的时候,监测注册在原始 socket 上的读写事件是否发生。BlockerPoller会和IO线程进程交互,防止IO线程忙等待消耗CPU
HiKariCP连接池
为什么快?
-
使用第三方字节码修改库Javassist来生成动态代理类
-
ConcurrentBag & FastList
ConcurrentBag :无锁设计、ThreadLocal 缓存、 CopyOnWriteArrayList、SynchronousQueue队列窃取
FastList:去除index检验、删除modCount统计、list遍历由后往前、扩容优化(容量够直接插入,必须扩容时直接扩容为*2)、只实现必要的接口
优化:根据sql执行复杂度分成长事务和短事务sql。长事务和短事务sql使用不同的连接池(多数据源配置)。长事务的连接池连接数可以设置的大一点,短事务的连接池连接数可以设置的小一点。
在Bash Shell中打开或关闭TCP / UDP套接字
1 | // 打开文件描述符6,关联到Socket tcp wwww.baidu.com 80,可读可写 |
Spring Cloud 应用如何注册到多个注册中心
https://cloud.tencent.com/developer/article/1425751
Mysql单表数据量不超过500万
为什么说建议msyql单表数据量不超过500万?这得从Mysql InnoDB存储引擎结构说起。Mysql InnoDB默认页大小是16KB,Mysql InnoDB的数据结构是B-Tree。一个高度为3的B-Tree能存储的数据量计算:
InnoDB默认是以主键建立聚族索引,叶子结点存储真正的数据,根节点和内部阶段只存储主键和指针。所以:16KB的页存储根节点Key个数大概是:16KB/8B(主键大小)+8B(指针大小)+8B(其他冗余)= 666,其中每个Key的指针指向1个中间结点,因此可以有666个中间结点,同理每个中间结点里的每个Key的指针也指向1个叶子结点,因此一共有666*666=443556个叶子结点。叶子结点存储真正的行数据和链表指针(方便范围查询)。以下面的Table举例:
1 | CREATE TABLE `t_ada_app_task` ( |
每个字段占用空间相加为:854+16(pre、next指针)+ 30(冗余)=900B(注意:由此可见varchar很占空间,尽量不要定义太大又无用的varchar字段),因此1个页可以存储的行为:16KB/900B=17。因此一颗高度为3的B-Tree叶子结点总共可以存储的数据行为:443556*17=750万
JMH函数级别性能测试
精准广告投放-Cookie-Mapping

①用户访问某个媒体(APP)的页面
②媒体(APP)向ADX发送广告请求(有时APP会向SSP发送请求,SSP再向ADX发送请求)
③ADX收到请求后,向对接的DSP分发请求
④DSP收到请求后,对请求带上的信息进行分析,然后向ADX返回竞价信息
⑤ADX根据DSP返回的竞价信息,通过一系列的判断,决定哪家竞价成功获得广告曝光机会,并将创意素材返回给媒体(APP)
⑥媒体(APP)收到ADX返回的创意素材信息后展现在用户访问的页面上
单机定时任务
JDK - Timer-单线程
JDK - ScheduledThreadPoolExecutor-线程池
Netty - HashedWheelTimer-时间轮、单线程、适用于对时效性不高的,可快速执行的,大量这样的“小”任务
Kafka - HashedWheelTimer-时间轮,1. 解决了Netty时间轮如果长时间没有到期任务,那么会存在时间轮空推进的现象(引入JDK的DelayQueue保存每个Bucket)。2. 解决了时间跨度大的问题(引入层级时间轮类似时针分针秒针的功能)
装饰器模式vs适配器模式
装饰器模式不改变要装饰的接口参数:例如:BufferedReader装饰Reader接口,并不修改接口,只做增强(Buffered)
适配器模式会将不同的输入参数适配到待适配到接口:例如InputStreamReader适配char数组输入到byte数组输入接口
模版方法vs策略模式
模版方法:一般在抽象类中定义好一种算法的执行流程骨架,具体每个步骤细节由子类继承实现:例如很多的抽象类AbstractCollection等
策略模式:不同的策略实现同一个接口,不同策略之间可以相互替换:例如不同的比较方式都实现Comparator接口
DNS
DNS放大攻击
DNS 放大可分为四个步骤:
- 攻击者使用受损的端点将有欺骗性 IP 地址的 UDP 数据包发送到 DNS 递归服务器。数据包上的欺骗性地址指向受害者的真实 IP 地址。
- 每个 UDP 数据包都向 DNS 解析器发出请求,通常传递一个参数(例如“ANY”)以接收尽可能最大的响应。
- DNS 解析器收到请求后,会向欺骗性 IP 地址发送较大的响应。
- 目标的 IP 地址接收响应,其周边的网络基础设施被大量流量淹没,从而导致拒绝服务。
预防DNS放大攻击
- 减少开放DNS解析器数目
- 源IP地址验证
DNS泛洪攻击
恶意攻击者向允许递归的开放DNS解析器发送大量伪造的查询请求,达到DDos效果
预防DNS泛洪攻击
丢弃未经请求或突发的DNS请求、白名单、黑名单等
DNS劫持
分本地DNS劫持、路由DNS劫持和直接攻击DNS服务器,目的就是向目标域名解析请求返回错误的IP地址
HTTPDNS
通过 IP 直接请求 HTTP 获取服务器 A 记录地址,不存在向本地运营商询问 domain 解析过程
- 从根本上避免了DNS劫持问题
- 提高域名解析效率
- 精确定位客户端地理位置、运营商信息,从而有效改进调度精确性。
Condition vs Object wait/notify
参考Conditon.java的注释说明,主要区别两点:
- Conditon可以在一个lock对象上提供多个Condition等待队列,比如生产者消费者模型中可以把notFull和notEmpty的等待队列设置为分开的两个,而使用Object的wait/notify只能使用一个等待队列来通知notFull和notEmpty事件
- Conditon提供了超时wait的方法和屏蔽中断的wait方法,而Object的wait/notify没有
Thread State
NEW
RUNNABLE
BLOCK (synchronized)
WAITING (wait、join、LockSupport.park)
TIMED_WAITING(wait with timeout、join with timeout、LockSupport.park with timeout)
TERMINATED
ReentrantLock是基于AQS实现的,AQS又是基于LockSupport实现的,所以ReentrantLock锁的状态是没有Block的,只有waiting或timed_waiting
Spring WebFlux
webflux基于netty的线程模型,利用少量的线程和等待队列来提高CPU的利用率;
webmvc基于多线程模型,利用开辟大量线程来提高CPU利用率;
对比下来:webmvc在线程数量太多的情况下,CPU耗时在线程切换上的时间增加,线程栈的内存使用量也增加,导致性能降低;而webflux只需要少量线程即可提高CPU利用率,且几乎没有多余的内存消耗,使得机器负载维持在一个稳定的水平。
Linux系统级配置
启动应用前一般需要对系统进行一些配置:
启动web监听端口一般需要设置:
-
fcntl设置O_NONBLOCK,
-
setsockopt设置SO_REUSEADDR,SO_REUSEPORT
-
设置TCP_NODELAY关闭Nagle算法,适用于实时性高的场景(Nagel算法会延迟小包的发送)
-
listen传递设置全连接队列backlog,其中backlog生效值为min(/proc/sys/net/core/somaxconn, listen param backlog),/proc/sys/net/core/somaxconn:系统限制每个端口的最大监听队列长度,默认128,太小,应该修改
-
使用netty-epoll的话,默认水平触发,根据情况设置水平触发还是边沿触发,select、poll实现的都是水平触发
-
系统参数设置半连接队列backlog:/proc/sys/net/ipv4/tcp_max_syn_backlog
-
系统设置/etc/sysctl.conf TCP接收缓存、发送缓存大小、keepalive_time、tcp_fin_timeout、tcp_tw_reuse、tcp_max_syn_backlog等
-
设置进行系统资源限制:可打开文件数,系统限制设置/etc/sysctl.conf fs.file-max,进程限制设置/etc/security/limits.conf
-
使用epoll时关注系统参数:/proc/sys/fs/epoll/max_user/watches

-
防火墙设置旧版本iptables vs 新版本firewalld,底层都是基于Netfilter
-
web运行用户权限配置
select、poll、epoll
select、poll每次均要把需要监控的fds传递给内核进行遍历然后返回有事件响应的fds,select限制1024个文件描述符(但是可以传超过1024个fds,只是会存在数据覆盖不安全,参考https://blog.csdn.net/dog250/article/details/105896693 https://programmer.group/5eb00f8e1ec61.html),poll没有这个限制
epoll,利用回调机制通过epoll_ctl添加fd感兴趣的事件,只需要添加这一次,epoll_wait返回有相应事件响应的fds
部署方式
-
蓝绿部署
特点:同时存在两个集群,两个集群中只有一个集群真正提供服务,另外一个集群测试、验证或待命
优势:服务文档,版本回退简单,适用于各种场景的升级,大版本不兼容升级的或迭代兼容升级
劣势:浪费硬件资源,需要同时有两个集群,如果集群比较大,比如有 1000 个节点,这种方式几乎不可用
-
金丝雀
特点:逐点部署,逐步替换线上服务
优势:小步快跑,快速迭代
劣势:只能适用于兼容迭代的方式,如果是大版本不兼容的场景,就没办法使用这种方式了
- AB 测试和上面两个不是一个范畴,不做比较。AB 测试是线上同时运行多个不同版本的服务,这些服务更多的是用户侧的体验不同,比如页面布局、按钮颜色,交互方式等,通常底层业务逻辑还是一样的,也就是通常说的换汤不换药。但是需要说明的一点,AB 测试可以采用上面两种部署方式的手法。
VIP
VIP即Virtual IP Address,是实现HA(高可用)系统的一种方案,高可用的目的是通过技术手段避免因为系统出现故障而导致停止对外服务,一般实现方式是部署备用服务器,在主服务器出现故障时接管业务。 VIP用于向客户端提供一个固定的“虚拟”访问地址,以避免后端服务器发生切换时对客户端的影响。
VIP的实现原理
- Master选举: 集群创建或者Master出现故障时,集群通过选举协议得到一个Master作为对外服务的节点
- 配置VIP: HA软件将VIP配置到Master节点的网卡上
- ARP广播: 主动对外广播ARP消息,声明VIP对应的MAC地址为Master的网卡MAC地址
Nginx+Keepalived高可用集群即使用了VIP技术
